この記事では、自分が数年Site Reliability Engineering (SRE)を実践しつつ、SREについて考えてきたことをまとめる。 先月開催されたMackerel Drink Up #8 Tokyoと先日開催された次世代Webカンファレンス 2019では、SREについて集中的に議論する機会に恵まれたため、脳内メモリにキャッシュされているうちに、SREに関する私的な論考をまとめておく。
(以降では、SRE本の原著にならい、技術領域名を指すときはSRE、職種名を指すときにSREsと表記する。)
SREとの関わり
なぜSREに関心をもったのか
2015年にメルカリさんがSREチームを発足したときに、SREsの存在を知り、SREsはシステム管理者、Webオペレーションエンジニア、インフラエンジニアといった既存の職種を置き換えていくものだと理解した。 当時、自分が注目したのは、SREsの仕事領域にソフトウェアエンジニアリングが含まれることと、業務時間に対してソフトウェアエンジニアリングが占める割合だった。 2014年前後では、SREsの存在が知られる前から、Infrastructure As Codeなどの概念の登場により、これからのインフラエンジニアは単にオペレーションをする人ではなく、コードを書いていくのだという認識が広まっていたと思う。
しかし、頭の中ではコードを書くことを認識していても、実際にソフトウェアエンジニアリングをやれている理想の状態と現状ではギャップがあった。 そこで、理想の状態を体現しているであろうGoogleやFacebookなどの企業が具体的なソフトウェアエンジニアリング時間の割合にまで言及していたことが自分の印象に残っていた。
また、SREを調べているうちに、システムの信頼性を100%にはできないという前提に基づき、エラーバジェットという自分にとっては新しい考え方を発見した。 これにより、最初は,SREとはこれまで定性的であったシステム運用に関する意思決定材料を、定量化するための方法論であるという印象をもったことも覚えている。
SRE本
しばらくして、2016年にはGoogleのSREsがSRE本の初版を出版した。 Web上の言説だけではSREをよく理解できていないと感じていたため、当時自分がもっていたソフトウェアエンジニアリングに集中するにはどうするかという問題意識を解決するために、主要な章を社内で輪読した。
輪読により、信頼性の具体的定義と指標であるSLI/SLO、SREsの日々のタスク分類(Software Engineering、System Engineering、Toil、Overhead)といった方法論を学んだ。 その結果、Googleのような先進的企業であっても、定常的な作業(Toil)をゼロにはできないし、ToilやOverheadが膨れ上がらないようにエンジニアリングに費やす時間を管理する組織的な方法論まで議論していることに親近感を覚えた。社内でSRE本輪読会を始めました / “GitHub - sysbooks/site-reliability-engineering: Readling book 'Site Reliability Engineer…” https://t.co/jGONejqMNM #sre
— yuuk1 (@yuuk1t) 2016年7月19日
さらにその翌年の2017年に日本語の翻訳書が出版された。 原書を読んだときは、答えを探すような気持ちで方法論をいかに自分の環境に適用できるかといった視点でしか読んでいなかった。 しかし、母語で読めたおかげか、見逃していたSREsの先人達の思いのようなものを感じ取れた。 特に序文、はじめに、1章では、なぜSREのような概念を構築するに至ったのかを知ることができる。
自分が考えるSRE
自分なりの問題意識とそれを解決するためのSREの概念の学習とその実践を通して、自分が考えるSREというものが徐々にできあがってきた。 以降では、自分が考えるSREとはなにかを書いていく。
SREとはなにか
SRE本の「はじめに」には、次のように書かれている。
それでは、サイトリライアビリティエンジニアリング(SRE)とはいったい何なのでしょうか。 この名前が、その内容をはっきりとは表現できていないことは認めざるをえません。
このあとに、説明が続いていくのだが、現時点では、一言で言い切るのは難しい。
もし自分が誰かにSREとはなにかと聞かれたら、今なら「サイト信頼性を"制御"するための技術」と答える。 ここでいう制御とは、信頼性を向上させることもできるし、維持することもできるし、低下させることもできることを指す。 過去にSREについて説明したときは、前者2つを説明することが多かった。
しかし、自分は、信頼性をあえて低下させることを前提とした方法論に着目した。 一般的な感覚でいえば、信頼性を下げるなんてありえないと思うかもしれないが、SRE本には、信頼性100%は基本的に達成不可能であるというドライな原則をもとに、4章ではSLOの過剰達成を避けるということが紹介されている。 実際、そんなに高い信頼性はいらないんじゃないかと思うことも正直あった。 信頼性と変更速度はトレードオフとなることがあり、障害の主な原因はヒューマンエラーであることを考えると、目先の信頼性をとりあえず向上させたければ、システムに変更を加えないほうがよいことになる。 これまでの自分の経験では、信頼性が低くて困るというよりはむしろ、暗黙的に信頼性100%を目指してしまい、システムを変更したいのに信頼性を低下させる過剰な恐れがあって万全を期すために変更が遅くなったり、そもそも変更しなかったりすることに困っていたことが多かった。 システムの変更には、そのあとの変更を速くするものも含まれるために、変更しないことにより、さらなる変更速度の低下をまねいてしまうことがある。
そうはいっても、ユーザーに明確に不便を感じさせるほど、信頼性を低下させるわけにはいかない。 システムの変更に対して、どこまで影響がでるかわからなかったり、問題があってもすぐに気づけない可能性があるなかで、変更を加えることは博打のようなものである。 しかし、変更影響が限られていたり、変更に対するテストがあったり、問題にすぐ気づけたり、問題があっても自動復旧できたり、その後の根本対策ができる体制があったりすることで、安心して変更できるようになる。 安心して変更できるのであれば、変更速度はあがっていくはずである。 このように、後述する信頼性の階層により信頼性を制御するための構造を構築しておくことで、信頼性を"制御"できている状態で、変更速度を高めていける。 100%の信頼性を構築することは難しいが、エラーを許容する前提があれば、あとは程度の問題ということになる。
なぜモニタリングをするのかのところ、深めていくと、監視されていることで安心して変更できるようになるため、変更速度が向上するっていう守りから攻めに転じらせるところがモニタリングのおもしろいところですよね / “PHPerのためのW…” https://t.co/uHRpyHPYPO
— yuuk1 (@yuuk1t) 2018年3月10日
信頼性とSLI/SLO
信頼性にはいくらかの定義のしようがある。 SRE本は、書籍"Practical Reliability Engineering"の定義である「システムが求められる機能を、定められた条件の下で、定められた期間にわたり、障害を起こすことなく実行する確率」を採用している。
SLIとSLOを適切に設定することは、SREを実践する上で最も重要である。 しかし、SLIが妥当かどうかを確かめることとSLOを計測することが難しいこともある。 例えば、SRE本では、SLIの例としてサービスのレイテンシが挙げられている。 レイテンシと一口にいってもリクエスト数は膨大なので、統計的な値を用いる必要があり、平均値なのか、中央値なのか、95パーセンタイルなのか、99パーセンタイルなのかといった選択肢がある。 さらに、リクエストの中にはロードバランサからのヘルスチェックや、ウェブクローラーからのリクエストなど、種類の異なるリクエストがある。 加えて、エンドポイントによってレイテンシの差が大きい場合に、エンドポイントごとにレイテンシを計測するか、まとめてしまうのかといった選択肢がある。
SLI/SLOがないとSREは始まらないので、ターゲットとなるシステム単位で、時間ベースの可用性目標やMTTR(Mean Time To Recovery)、障害発生回数など計測が比較的簡単なものから計測しはじめるとよいと思っている。 そこから、四半期ごとなど定期的にSLI/SLOが適切かをプロダクトオーナーとSREsが見直していけばよい。 SLI/SLOの設計の具体的な例などは、書籍The Site Reliability Workbook*1が詳しい。
信頼性の階層
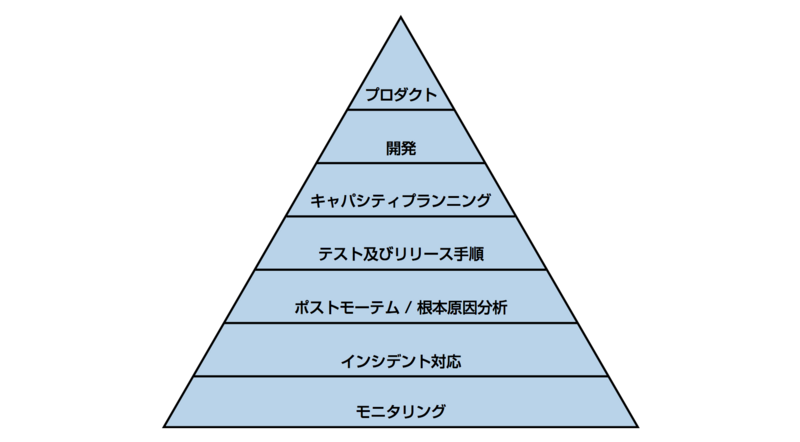 (Betsy Beyer et. al.編, "SRE サイトリライアビリティエンジニアリング", オライリージャパン, p108図III -1サービスの信頼性の階層)
(Betsy Beyer et. al.編, "SRE サイトリライアビリティエンジニアリング", オライリージャパン, p108図III -1サービスの信頼性の階層)
信頼性を計画的に構築するには、上記のような信頼性階層を構築する必要がある。 まず、信頼性構築のための基盤となるのが、信頼性を測定する手法としてのモニタリングだ。 これがなければ、サービスがReliableな状態にあるのかがそもそもわからないし、監視項目にもれがあれば、ユーザーに影響があるのにそれに気づけていないことになる。 信頼性を高めたいもしくは安心して変更していきたいという問題意識がある場合、まずは、モニタリングから見直し、この階層の下から上で登っていくとよいと思う
信頼性と変更速度の両立
先に、信頼性と変更速度はトレードオフとなると書いたが、ソフトウェアエンジニアリングによりこれらを両立できることがある。 人間の動作時間は計算機の動作時間に比べて遅いため、復旧時間を短くするには、オペレーションをできるだけソフトウェアに任せるのが筋が良い。 仮にSLIとしてMTTRが設定されているとすると、ソフトウェアエンジニアリングにより信頼性が向上していると言える。 オペレーションが自動化されていると、普段の変更も高速化し、結果として信頼性と変更速度のそれぞれの向上を両立できると言える。
SREがエンジニアリングのなかでもソフトウェアエンジニアリングを重視しているのは、トレードオフの解決のためであると考えている。
変更速度の計測
信頼性が十分高い状態であれば、次は変更速度を計測する必要がでてくる。 変更速度が計測できていないと、信頼性を高くできているがそのために労力をかけすぎているケースに気づけない可能性がある。
そこで、SRE本に書かれているように、SREが、ソフトウェアエンジニアのチームが従来のシステム管理を再構成したものととすると、もともとソフトウェアエンジニアがやっているプロダクト開発のアプローチに着目した。 DevOpsの文脈においても、プロダクト開発(Dev)のアプローチである継続的インテグレーションなどがOpsにて採用されていった経緯もある。
変更速度を計測するために、アジャイル開発の手法をとりいれたことがある。 具体的には、プロダクト開発と同様に、ビジョンを設定し、機能開発のためのロードマップを設定し、スプリントごとにバックログを積み、プランニングポーカーによりバックログに見積もりポイントを設定し、ベロシティを計測するといったものだ。(僕は、書籍アジャイルな見積りと計画づくり ~価値あるソフトウェアを育てる概念と技法~ だけを読んでアジャイル開発を勉強した。) 直接の経緯としては、SRE本にはToilの割合は50%以下に抑えよというプラクティクスがあり、Toilの割合がどの程度かを確認する必要があった。 しかし、Toilは短時間である、割り込みである、数が多い、またはToilとEngineeringの区別は実は難しいといったように計測が難しくなるような性質をもつ。 したがって、直接Toilを計測するのではなく、ベロシティを計測することにした。 ベロシティが低下したスプリントには、どんな要因があったかを確認し、その要因を取り除くようなタスクをバックログに積んだりもしていた。 要はやりたいことができていればよいので、それらを直接的に計測しようということである。
これらは横串のプラットフォームチームとしての取り組みだったが、サービス開発チームにおいても同様だと思う。 サービス開発チームにおいては、すでにプロダクトオーナーが存在し、オーナーがロードマップを決定していることもある。 そのときは、SREとしてのロードマップも、プロダクトのロードマップに組み込むという考え方になる。
信頼性と費用
変更速度以外にも、信頼性(レスポンスタイム)と費用のトレードオフがある。 例えば、インスタンスサイズを大きめにしたり、インスタンスの個数を大きめにしたりすると、突発的な負荷に耐えやすくなり、信頼性は向上する。 しかし、キャパシティを余分にもつことで費用は高くなってしまうということがある。
クックパッドさんの事例では、実験をした上で、ユーザー影響を定量化し、プロダクトオーナーとの協議の末、あえてGPUからCPUに移行されていた。 本番/ステージング環境GPUぼくめつ大作戦 - クックパッド開発者ブログ これは、信頼性を制御した上で、費用を削減するというSREの取り組みの例といえる。
技芸から工学へ
書籍「ウェブオペレーション」では、まえがきにて著者が次のように述べている。
ウェブオペレーションは技芸であり、科学ではない。 正規の学校教育・資格・標準は(少なくとも今はまだ)ない。 我々のやっていることは、学習にも習得にも時間がかかり、その後も自分自身のスタイルを模索しなければならない代物である。 「正しい方法」はどこにも存在しない。 そこにあるのは、(とりあえず今は)うまくいくという事実と、次はもっと良くするという覚悟だけだ。
一方で、SRE本では、序文にて著者の一人であるMark Burgess*2は次のように述べている。
Principles of Network and System Administration[Bur99]の導入部で、システム管理はヒューマンコンピュータエンジニアリングの形の一つだと私は主張しました。 レビューアの中には「まだそれはエンジニアリングと呼べるほどの段階には来ていない」と強く否定する人もいました。 この時点では、私はこの分野は見失われて、独自の魔術師的な文化にとらわれ、進むべき方向が見えなくなっていると感じていました。 しかし Google は明確に線を引き、来たるべきシステム管理の姿を現実の存在にしたのです。 そして見直された役割がSRE、すなわちSite Reliability Engineerと呼ばれるものでした。
"エンジニアリングと呼べるほどの段階には来ていない"、"独自の魔術的な文化"という言葉が指すのは、前述でいうところの技芸にあたると解釈している。 自身の経験においても、古いバージョンのMySQLクラスタの切り替え作業を曲芸のようなオペレーションで乗り切ることもあった。*3
SREの登場により、技芸(Art)から工学(Engineering)へと移り変わる兆しがみえてきたように思う。
最初は、工学ではなく科学と書いていたが、科学は文献によっては理学のみを指すこともあるようなので、工学とした。 SREのEはEngineeringなので、工学なのは当たり前なのだが、これまではエンジニアリングといいつつも、技芸やテクニックのみになりがちであったように思う。 とはいっても、技芸が不要ということではなく、これからは、工学と技芸の両輪で回していくことになると考えている。
- 工学と理学の違い
- http://www.el.gunma-u.ac.jp/~kobaweb/lablife/kougaku3.pdf
- 工学と技術 | Adachi Lab.
- 工学 2014.02.16-02.22 | 原島 博 ホームページ
まとめと今後
この記事では、自分がSREに関心をもった経緯と解釈の変遷、自分なりのSREのあり方をまとめた。 このように、信頼性を軸に据えることにより、我々のやっていること、やろうとしていることをずいぶん体系だてて説明できるようになったと感じている。 ウェブオペレーションでは、ネットワーク・ルーティング・スイッチング・ファイアウォール・負荷分散・高可用性・障害復旧・ TCPやUDPのサービス・NOCの管理・ハードウェア仕様・複数のUnix環境・複数のウェブサーバ技術・キャッシュ技術・データベース技術・ストレージインフラ・暗号技術・アルゴリズム・傾向分析・キャパシティ計画立案などの技術を組み合わせて、システムを運用する。 しかし、我々はデータベースの開発者ではないし、BGPオペレーターでもないし、OS開発者でもないし、ハードウェア技術者でもない。 では何をする人なのかというと、今ではSREの専門家といえばよい。*4
今後は、2019年の展望でも紹介した「故人の跡を求めず 故人の求めたるところを求めよ」という言葉でいうと、単に方法論を適用するだけに留めず、SREsの先人の求めたるところを求めていきたい。 組織としては、工学としてのアプローチをとりいれていくことになるだろうし、巨大クラウド事業者のサービスの発展により全員がSREをやっていくことになると思う。 そんな中で、今SREsである人たちは、要素技術がクラウド事業者に取って代わっていき、良くも悪くも仕事が減っていく中で、SREをどうやって楽しんでいくかというところが重要になってくるだろう。 ウェブの世界での技術の進化の方向性としては、ウェブシステムの運用自律化に向けた構想 - 第3回ウェブサイエンス研究会 - ゆううきブログに私見をまとめている。 他には、システムのすべてが機械により自律制御されるビジョンに対するアンチテーゼとして、あんちぽさんの なめらかなシステムを目指して が参考になる。 また、自分自身としては、分散型データセンターOSとリアクティブ性を持つコンテナ実行基盤技術のこれから - 人間とウェブの未来に書かれているようなウェブの下の階層にて、分散型データセンターのような新しい基盤を前提にSRE Researcherをやっていくことになると思う。
最後に、SRE本の書評や読み方として、自分の考えに近いものをみつけたので以下にリンクを紹介しておく。
次世代Webカンファレンス2019での、@kannyと@deeeetと議論した様子は 録画で視聴できる。
SRE本読みながら、出世はオーバヘッドとか言って大喜びしてる
— yuuk1 (@yuuk1t) 2016年8月2日
SRE本に、少数の英雄的メンバーのバーンアウトにより、ガタガタのシステムの可用性を強制的に引き上げられるとか書いてて、大喜び
— yuuk1 (@yuuk1t) 2016年8月4日
SRE本呼んでたら、「クリエイティブなssh」「技術的負債のコレステロール」とかでてきて大喜び
— yuuk1 (@yuuk1t) 2016年8月17日
冒頭にはいろんな組織に適用できますとあるけど、超大規模システムだからこその前提が敷かれていることもある。なので、部分的な要素を真似してそれでSREですってのもなんか違う気がしていて、自分の組織にあわせてデザインしましょうという気持ちになっている。
— yuuk1 (@yuuk1t) 2017年1月16日
SRE サイトリライアビリティエンジニアリング読んでる 日本語でさくさく読めて最高
— yuuk1 (@yuuk1t) 2017年8月11日
31章"SREにおけるコミュニケーションとコラボレーション"で、平均以上に有益なミーティングの例として、プロダクションミーティングというものが挙げられていてこれははてなでやっているPWG(パフォーマンスワーキンググループ)とだいたい同じでおおってなった
— yuuk1 (@yuuk1t) 2017年8月11日