さくらインターネット Advent Calendar 2020の23日目です。
現時点では最新版のRedis 6.0のRedis Clusterに対して、Go言語の代表的なRedisクライアントライブラリであるgo-redisからアクセスしたときに、性能が深刻なレベルで劣化しました。 この記事では、ミドルウェアを利用したGo言語アプリケーションの性能劣化に関する問題調査の事例として、この性能劣化を修正するまでの話をまとめました。
go-redisへのPull Requestはhttps://github.com/go-redis/redis/pull/1355です。
はじめに
半年ほど前の論文の締め切りに追われていたある日、評価実験のためにRedisを使った時系列データベースのプロトタイプを開発していました。 ベンチマークツールでプロトタイプの性能を測定したところ、単一インスタンスのRedisに対して想定した結果を得られました。
そこで、意気揚々と、スケールアウト性能を評価するために、複数のRedisインスタンスにデータを水平分割可能なRedis Clusterを利用して、スループットを計測しました。 ところが、信じがたいことに、単一インスタンスに対するスループットよりも、クラスタ化することでかえって、1/10倍ほどスループットが低下する結果となりました。
最初は、単一インスタンスとRedisクラスタとの処理の差分に着目しました。 実験では、GoアプリケーションとRedisプロセスのCPUリソースを全く使い切れていなかったため、ネットワークI/Oに関わるボトルネックにあたりをつけました。
Redisクラスタは、水平分割のために、コマンドが対象とするキーとノードを対応させる必要があります。 キーとノードの対応を直接管理するわけではなく、ノードの増減に対応しやすいように、ハッシュスロットという固定数のスロットが利用されます*1。 ノードが自身に割り当てられたハッシュスロットに対応しないキーを含むコマンドを受信したときに、クライアントへリダイレクトするように指示します。 なるべくリダイレクトさせないほうが望ましいため、go-redisはキーがどのハッシュスロットに属するかを計算した上で、適切なノードに最初からコマンドを送信します。
Redis Cluster化したら一気にスループット落ちたぞ… redisパイプライン内でクライアント側がキーとハッシュスロットのマッピングに応じて振り分けてる処理で詰まってるのかな...
— ゆううき (@yuuk1t) 2020年6月2日
クライアントによるノード選択がうまく動かずに、コマンド発行のたびにリダイレクトしているのではないかとあたりをつけました。 しかしながら、go-redis内でprintデバッグしても、リダイレクトを観測できませんでした。
このように、その時点で持ってる知識から直感であたりをつけて問題調査をしても、試行錯誤の回数が増えて、結局遠回りなりました。
そこで、推測せずに、計測することにしました。
計測のために、Go言語標準のトレーシングツールであるExecution tracerを利用しました。
pprofで取得した結果をgo tool traceに食わせると、goroutineの実行状況、特にメソッドの呼び出し関係とメソッド単位の実行時間を可視化できます。
go tool traceの分析結果
go tool traceはView Trace、Goroutine Analysis、Network blocking profile、Synchronization blocking profile、Syscall blocking profile、Scheduler latency profileなどのトレースのビューがあります。
次の画像は、実際のプロトタイプの動作が可視化されたビューの種類ごとの結果です。
ビューによっては、みやすさのために、ビューの一部を拡大して表示しています。
View Traceは、Goroutine数、ヒープメモリ量、スレッド数、プロセスごとのGC回数やどのコードが実行されているかなどの時間変化を表示します。
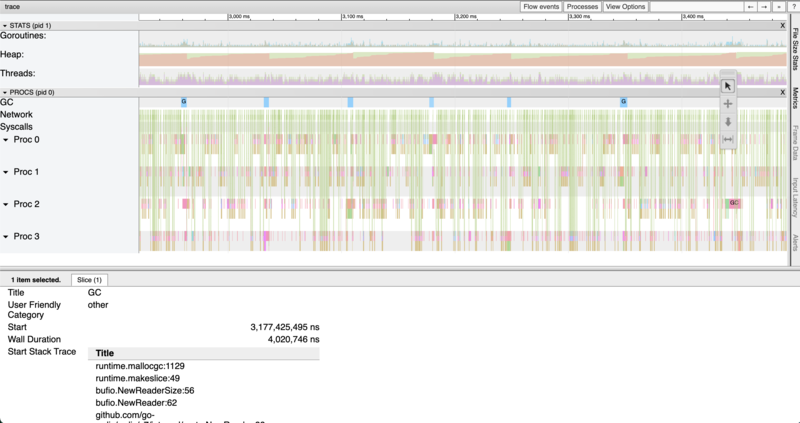
Goroutine Analysisは、プロファイル期間に実行されたgoroutineの数を、goroutineが起動された関数ごと、かつ、全体の実行時間の割合の降順に表示します。
 (Goroutine Analysis)
(Goroutine Analysis)
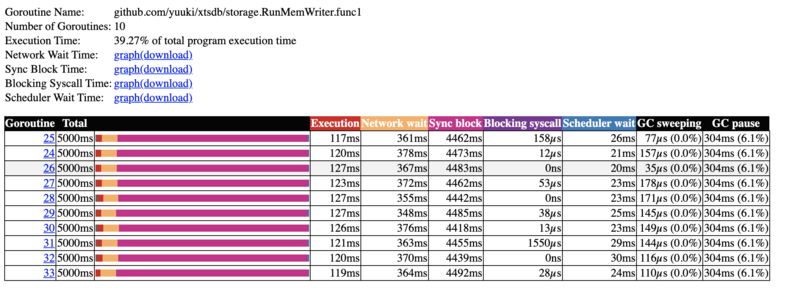
Network blocking profoleは、ネットワークI/O待ち時間をメソッドの呼び出し関係とともに表示します。
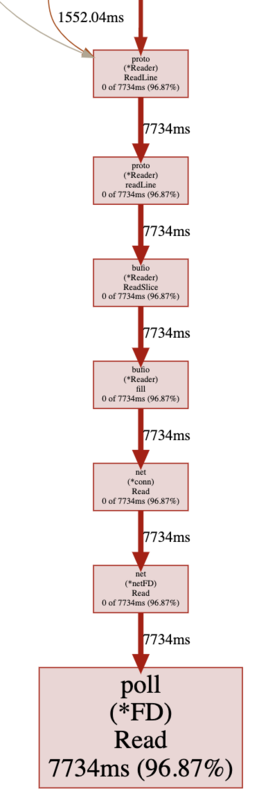 (Network blocking profole)
(Network blocking profole)
Synchornization blocking profileは、排他ロックなどの同期プリミティブにより待ちに入った時間をメソッドの呼び出し関係とともに表示します。
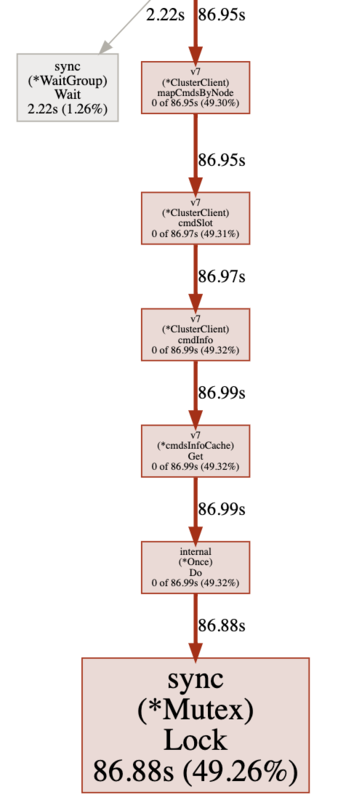 (Synchornization blocking profile)
(Synchornization blocking profile)
Syscall blocking profileは、OSカーネルに対するシステムコールのブロック時間をメソッドの呼び出し関係とともに表示します。
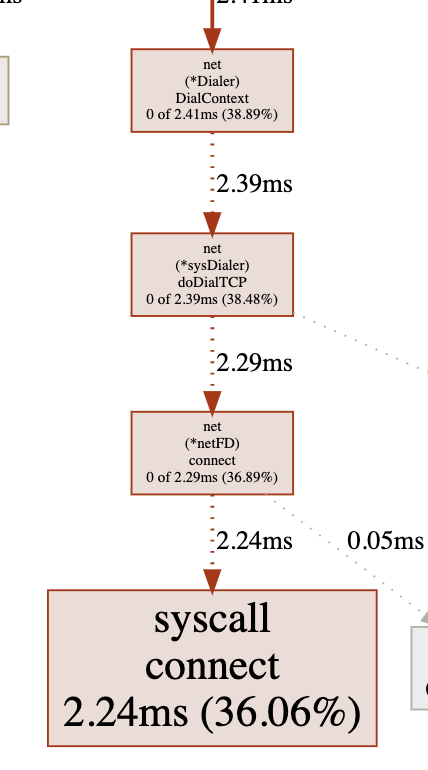 (Syscall blocking profile)
(Syscall blocking profile)
Scheduler latency profileは、Goの処理系のスケジューラのスケジューリング遅延時間を表示します。
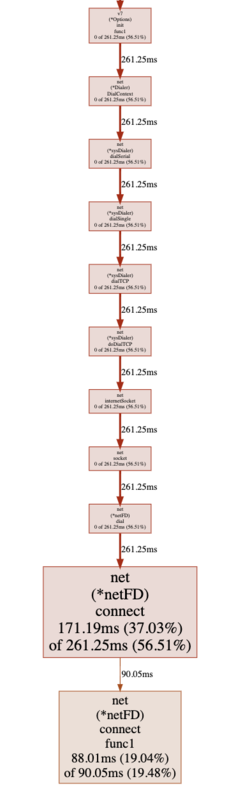 (Scheduler latency profile)
(Scheduler latency profile)
各ビューをみると、go-redis内のミューテックスロックと画像では見えづらいですがRedisのパイプライン処理内のネットワークI/O待ちがボトルネックとなっていることがわかります。 profile系のビューでは、上の画像では範囲外になっていますが、自分が書いているアプリケーションのコードのメソッドも表示されるので、ライブラリの内部的な処理と紐付けることができます。
ミューテックスロックの調査
このロックは何のためにどこで利用されているのでしょうか。
sync.Mutexの呼び出し元は、ClusterClient.mapCmdsByNode -> ClusterClient.cmdSlot -> ClusterClient.cmdInfo -> cmdsInfoCache.Get -> internal.Once.Do の順となっています。
mapCmdsByNodeは、パイプライニングのキーに関する制約にあたらないように、適切なノードにコマンドを振り分けるために、ノードとコマンドの対応を生成します。
その一連の処理の中で、コマンド引数の中のキーの位置を知る必要があります。
go-redisではCOMMANDコマンドを利用することにより、動的にコマンドとキーの位置の対応関係を取得できます。
コマンドとキーの位置の対応関係は、Redisのコード内で静的に決定されるため、Redisサーバにアクセスするたびに、取得する必要はありません。
そこで、COMMANDコマンドの結果をキャッシュするのが、cmdsInfoCacheです。
おそらくは、複数のgoroutineからCOMMANDコマンドがRedisサーバに殺到しないように、ミューテックスロックを獲得したのちに、COMMANDコマンドを送信しています。
このミューテックスロックの箇所がボトルネックということは、COMMANDコマンドをキャッシュできずに、毎回COMMANDコマンドを送信しているのではないか?と疑いました。
実際に、printデバッグすると、パイプラインを実行するたびに、たしかにCOMMANDコマンドを送信していました。
なぜこのようなことが起きているのかを探っていくと、COMMANDコマンドの結果を取得するメソッドがエラーとしてredis: got 7 elements in COMMAND reply, wanted 6を返していましたhttps://github.com/go-redis/redis/blob/v7.2.0/cluster.go/#L1534-L1540。
このエラーが上位の呼び出し元に伝搬する過程で、エラーが無視され、COMMANDコマンドの結果をnilとして返却していました。https://github.com/go-redis/redis/blob/v7.2.0/cluster.go/#L1546-L1549
この調査により、キャッシュできずに、毎回COMMANDコマンドを送信していたことが確定しました。
エラーの分析と修正
前述のエラーの生成元は、COMMANDコマンドの結果のパース処理でした。ここでエラーになるということはnが期待する6ではなかったことを指します。
func commandInfoParser(rd *proto.Reader, n int64) (interface{}, error) {
if n != 6 {
return nil, fmt.Errorf("redis: got %d elements in COMMAND reply, wanted 6", n)
}
# https://github.com/go-redis/redis/blob/v7.2.0/command.go/#L1936-L1939
このnの値は、COMMANDコマンドが出力する、各コマンドごとのメタ情報の要素数を指しています。
そして、Redis 6.0からはこの要素数が6から7に増えていました。https://github.com/redis/redis/commit/c5e717c637cbb1c80e1259560ebf995fb7920628
このRedis本体の変更により、先程のエラーが生成されるようになっていました。
この変更でCOMMANDコマンドの返却する要素数が6 -> 7になってる。 https://t.co/4n1I4Xk1et
— ゆううき (@yuuk1t) 2020年6月4日
そのせいで、go-redisの https://t.co/MTY2YIvxHS のif文でエラーを返すようになってる。エラーになるとキャッシュされないから毎回204エントリあるredisのコマンドリストを取得している...
実際に、コマンドを叩いて確認してみます。 Redis 5.0.8は、次のように要素数6となりました。
127.0.0.1:6379> COMMAND INFO xadd
1) 1) "xadd"
2) (integer) -5
3) 1) write
2) denyoom
3) random
4) fast
4) (integer) 1
5) (integer) 1
6) (integer) 1
一方で、Redis 6.0.1では、次のように要素数が7となりました。
127.0.0.1:6379> COMMAND INFO xadd
1) 1) "xadd"
2) (integer) -5
3) 1) write
2) denyoom
3) random
4) fast
4) (integer) 1
5) (integer) 1
6) (integer) 1
7) 1) @write
2) @stream
3) @fast
以上により、エラーの修正内容は、要素数7のケースの対応を追加するだけだとわかりました。 修正の結果、プロトタイプにおいて、想定するスループットを得ることができました。
最終的に、この修正内容をgo-redisへPull Requestとして提案して、提案が取り込まれました。
go-redisの↑の問題を解決するPRを投げた。 https://t.co/mnsESAO66P
— ゆううき (@yuuk1t) 2020年6月5日
参考
- An Introduction to go tool trace
- golang でのデバッグに非常に便利な go tool trace - 理系学生日記
- go tool traceでgoroutineの実行状況を可視化する - ( ꒪⌓꒪) ゆるよろ日記
- RedisサーバのCPU負荷対策パターン - ゆううきブログ
まとめ
Redis 6.0のクラスタにおいて、go-redisで接続したときの深刻な性能劣化に対して、pprofを利用して、ボトルネックを発見し、ソースコードを調査した上で、修正しました。 今回の問題は、Redis 6.0以降のクラスタに対して、go-redisから接続すると必ず発生するものでしたので、小さな修正のわりには、潜在的な影響範囲はそれなりに大きかったように思います。 それを修正できたので、自分としては満足感を得ました。
僕は、自分が開発したわけではない既存のOSSの、バグや改善点を発見することがどうも苦手なため、既存のOSSにパッチを投げることに対して苦手意識をもっています。 実際、Pull Requestを投げる頻度は、高々年に1,2回程度です。 OSSの問題を発見して修正パッチを息を吸うように投げられる人は、おそらくソフトウェアの問題を発見する目が鍛えられているのでしょう。
研究を進める上では、実験結果をよくするために、どうしても所定の性能がほしかったり、研究成果の一部を世の中で使ってもらうためには、既存のOSSを改善することが必要になります。 このような目的意識から駆動される、ある種の強制力をうまく利用して、苦手ながらもOSSコミュニティへ少しずつ貢献していきたいですね。
振り返ってみると、サーバ側のAPIの仕様変更にクライアントライブラリが追従できていなかった故に発生した問題ということになります。 仕様変更を異なる組織や個人が管理するクライアントライブラリまでに反映させるのは、コミュニケーションのレベルで、一般的に難しい問題です。 性能の問題と捉えると、CI/CDのプロセスに性能測定をして、異常があれば通知することも一つの手です。 しかし、どの程度遅くなれば、異常とみなすのか、性能値を評価するには、CI/CD環境で一貫したハードウェアリソースを利用しつづけなければならない、様々なアクセスパターンが考えられる中で、どの程度テストケースを網羅すべきかなど考えることはたくさんあります。
このように、ちょっとした工夫では解決しづらい問題を、研究開発で解決する問題と捉えると、おもしろいかもしれません。
*1:水平分割(パーティショニング)におけるノードのパーティション割り当て戦略について詳しくは、「Martin Kleppmann著,斉藤太郎 監訳,玉川竜司 訳, データ指向アプリケーションデザイン――信頼性、拡張性、保守性の高い分散システム設計の原理, 6.4.1.2 パーティション数の固定, オライリー・ジャパン, 2019」を参照してください。