近年,汎用計算の高速化のためのアクセラレータとして注目されているGPUを,ネットワーク処理に適用する一環として,サーバサイドのSSL処理に注目した論文を読んだので,内容を軽く紹介します.

SSLShader: Cheap SSL acceleration with commodity processors Proceedings of the 8th USENIX conference on Networked systems design and implementation 2011
なお,評価に使われた実装の一部のソースコードが公開されています.
紹介
背景
SSL(Secure Socket Layer)ですがHTTP2.0のたたき台となっているSPDYなどではSSL(正確にはTLS)の使用が前提となっており,今後サーバサイドでのSSL対応の要求は高まってくると思います.
SSLの暗号処理部分はCPUバウンドな処理なので,CPU負荷の分散のために,高速なハードウェアアクセラレータを用いたり,複数の低速なソフトウェアアクセラレータを用意して,それらに対してロードバランサにより処理を並列分散したりします.
動機
しかし,ハードウェアアクセラレータの問題として価格コストが高い,新暗号アルゴリズムの対応など柔軟性に欠ける,ロジックがハードウェアで実装されているので,障害原因を突き止めにくい,ということがあります. さらに,ソフトウェアアクセラレータを複数台並べるには,これも複数台分のコストがかかりますし,システム構成も複雑になるので運用しづらいという問題があります.
提案手法
これらの問題点を解決するのが,論文の主題となっているSSLShaderです. SSLShaderは,暗号化部分を安価なGPUにオフロード機能を備えたSSLリバースプロキシであり,高負荷時に高スループット,低負荷時に低レイテンシとなるように設計されています.
GPUの一般の話は下記スライドが参考になると思います.

高負荷時に高スループット,低負荷時に低レイテンシというのが論文中で何度も繰り返されており,論文の重要なポイントとなっています. これをどのように達成するのかというアイデアをまとめると下記のようになります.
- 高スループットを達成するためには数百個(最新世代では1000個以上)のGPUコア(単体コアの性能はCPUに劣る)を活用しなければならないため,並列化が重要
- 各クライアントから発行されるSSLリクエストは独立しているため,各SSLリクエストは並列に処理可能.したがって,GPUに複数のリクエスト分の暗号処理をまとめてつっこむ.
- 低負荷時(同時接続数が少ない)ときはGPUに渡すタスク量が小さすぎるためCPUのみのほうがスループットが高く,逆に高負荷時にGPUに渡すタスク量が多すぎてスループットがでないということがある.よって,CPU1コアのほうがスループットが高くなるような負荷であれば,CPUに任せる.一方,GPUに渡すタスク量が多過ぎないように,適当なところでGPUに渡すタスク量に上限を設ける.
上記のアイデアを実現するためのシステム構成として以下の図のようなシステムが提案・実装されています.
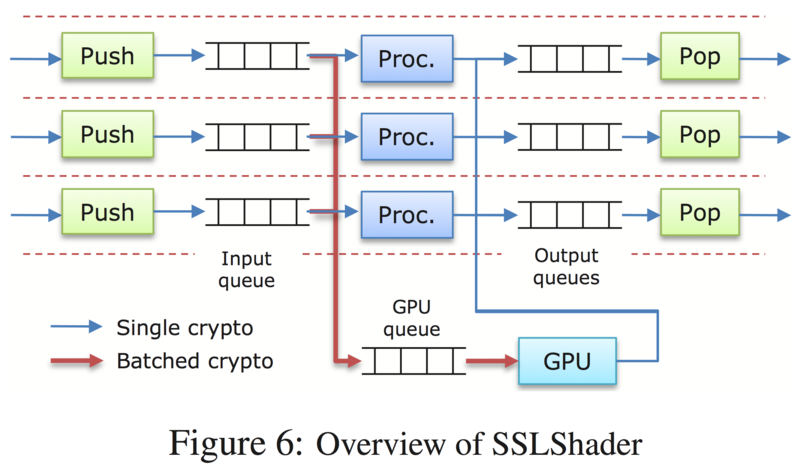
CPUコア数分のワーカスレッド(実験環境では12個)と,GPUの個数分のGPUインタフェーススレッドを用意します. 各ワーカスレッドは個別にInput queueをもち,GPUインタフェーススレッドはGPU queueをもちます. どちらのキューにもRSEやAESなどの暗号処理タスクが格納されます. ワーカスレッドは基本的に,I/Oイベントを処理(図のPushとPop)し,空いている時に暗号処理(図のProc)を実行します. さらに,キューに含まれるタスク数が多い時はGPU queueにInput queueの内容を移行させます. GPUインタフェーススレッドは,GPU queueを見て最も先頭にあるタスクの暗号アルゴリズムと同じ暗号アルゴリズムのタスクをまとめてGPUにオフロードします. (この辺,異なる暗号アルゴリズムであっても,GPUのリソースが余っていれば同時にGPUに処理させたりしないのか疑問.)
なお,キューに含まれるタスク数の多寡は,静的に設定した閾値により決定されます.値自体はベンチマークテスト時のconfigureで測定した上で設定されるようです.
以上のようなパイプライン処理で,高スループット低レイテンシを達成されています.
評価
SSLShaderの比較対象として,lighttpd with OpenSSLが使われています. クライアント7台からabコマンドを叩いて対象のSSLプロキシに負荷をかけています.
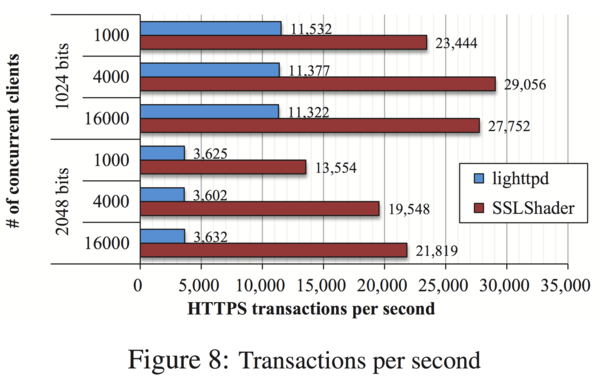
まず,スループットの評価ですが,クライアントからの同時接続数を変化させたときのSSL transactions / s (TPS) を測定したものになっています. RSA 1024bitで,SSLShaderがlighttpdの2〜2.5倍速く,RSA 2048bitで,約4〜6倍速くなっています.
次に,レイテンシ(レスポンスタイム)の評価です. 負荷が高いケースと低いケースで提案手法の効果をCDFで評価しています. 例えば,80%のときはコネクション100本のうちの80本はレイテンシ◯msで返せるということがわかります. 凡例の括弧内は(コネクション数,TPS)となっています.TPSはabコマンドに手を入れて一定のTPSでリクエストを投げられるようになっています.
低負荷時は両方とも,90%程度のコネクションが数ms程度程度で返せています. 高負荷時はSSLShaderのほうがレイテンシは小さくなっています.
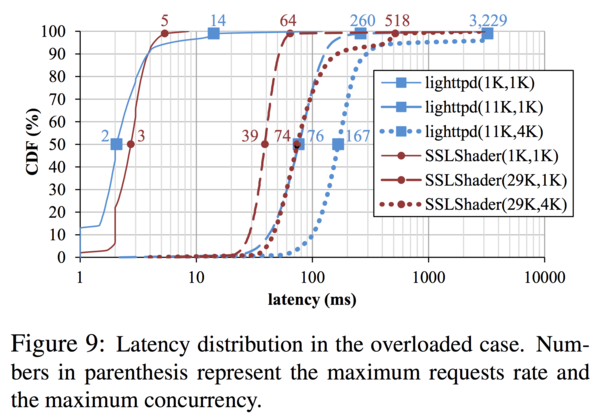
以上より,特に高負荷時においてはSSLShaderの優位性が確認されています.
スライド
研究室の輪講用につくったスライドです.細かすぎると感じた内容についてはいつかとばしています. 読み違い・誤解などが含まれている可能性があります. 特にSSLの認証周りはサッパリなので結構適当です.
関連研究
GPUをネットワーク処理に応用するという研究として,ルータのルーティンやIPSecの暗号化処理をGPUで高速化するというものがあります. SSLShaderと同じ研究チームのようです.
